Markedet forklarer meget lidt
S&P 500 har statistisk signifikant sammenhæng med Novo, men forklaringskraften er så lav, at markedet ikke kan være hovedforklaringen på de store bevægelser.
(Analysen er selfølgelig tidsbegrænset til 9. juni, 2026) Kan man sige noget meningsfuldt om Novo Nordisk-aktien, som ikke bare gentager det åbenlyse? Mit udgangspunkt er simpelt: først ser jeg på overfladen — kursudvikling, beta og volatilitet — og derefter prøver jeg at udfordre det billede med regression, regimeskift, abnormal returns og sammenligning med Eli Lilly. Målet er ikke at lave en aktieanbefaling, men at forstå hvorfor Novo bevægede sig, som aktien gjorde.
Projektet starter i et klassisk finance-spørgsmål, men behandles mere undersøgende end konkluderende.
I hvilken grad kan Novo Nordisks kursudvikling forklares af generelle markedsbevægelser, og i hvilken grad peger data i stedet på virksomhedsspecifikke begivenheder, regimeskift og konkurrencedynamik i GLP-1-markedet?
Jeg starter med det man umiddelbart kan se i kursgrafen. Derefter tester jeg, om det visuelle indtryk faktisk holder, når man måler det med beta, R², split-period regression, rolling volatilitet, event study og en sammenligning med Eli Lilly. Det gør analysen mere blog-agtig og undersøgende: først hvad ser jeg?, derefter hvorfor kan det være sådan?
Hypoteserne er ikke “sandheder”, men arbejdsspørgsmål, som tallene kan støtte eller svække.
S&P 500 har statistisk signifikant sammenhæng med Novo, men forklaringskraften er så lav, at markedet ikke kan være hovedforklaringen på de store bevægelser.
Novo opfører sig anderledes før og efter aktiens peak. Hvis beta, alpha og usikkerhed ændrer sig, bliver full-period regressionen for grov.
Sammenligningen med Eli Lilly kan vise, om Novo ikke kun bevæger sig mod markedet, men også mod en direkte konkurrent i obesity/GLP-1-markedet.
Data hentes via yfinance, og analysen gennemføres på daglige procentvise afkast.
Novo Nordisk B, S&P 500 og Eli Lilly hentes som justerede slutkurser. Kursgrafen indekseres til 100 for at gøre serierne sammenlignelige.
Modellen er Novo-afkast = alpha + beta · S&P 500-afkast. Jeg fokuserer især på R², fordi den viser, hvor meget modellen faktisk forklarer.
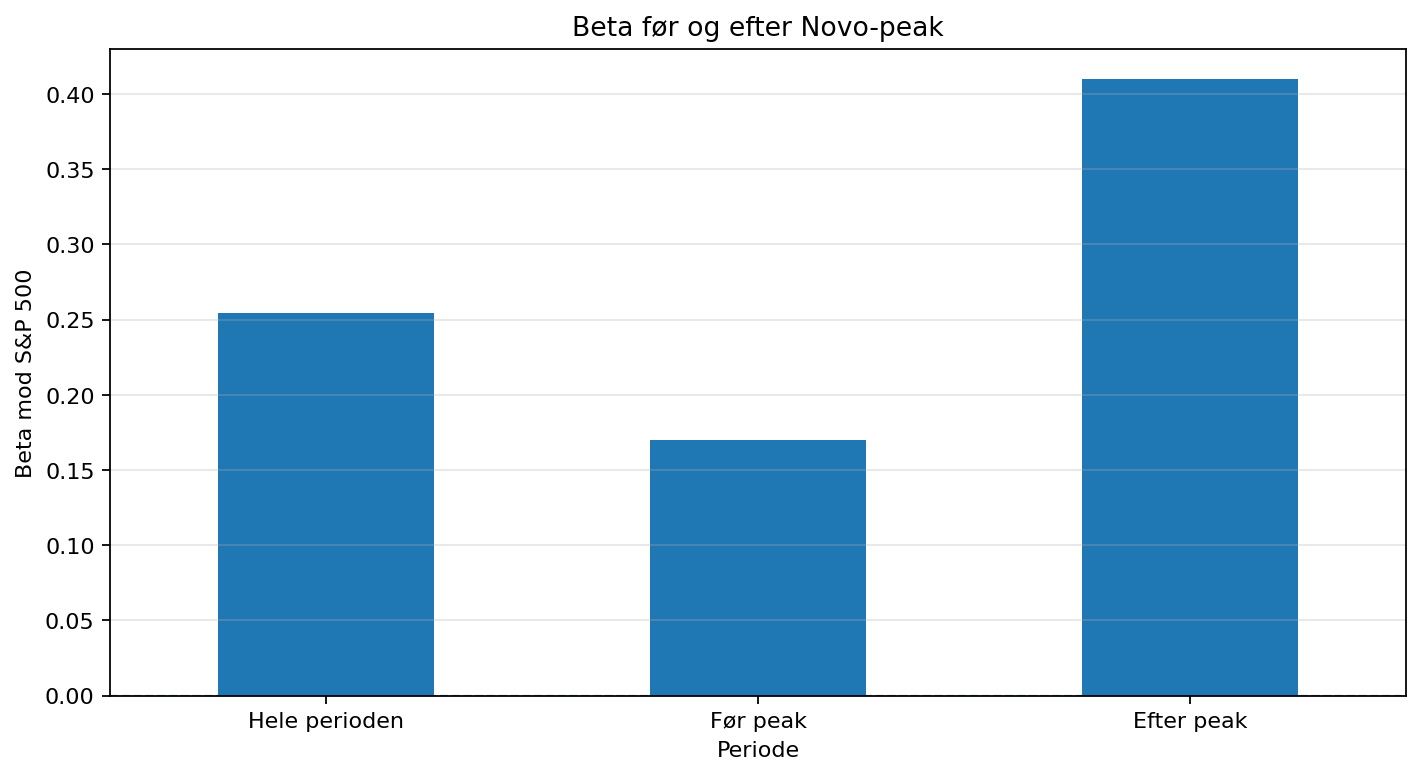
Perioden deles ved Novo-peak omkring 26. juni 2024. Det tester, om relationen til markedet ændrer sig efter den store optur.
For fem centrale begivenheder beregnes kumulativ abnormal return i vinduet [-1,+3] handelsdage, relativt til et 252-dages estimeringsvindue.
Analysen er ikke kausal. Den bruger daglige lukkekurser på tværs af markeder med forskellige tidszoner, og udvælgelsen af “peak” og events er delvist ex post.
Nedenfor er analysen formuleret som en undersøgende fortolkning med konkrete tal.
Den indekserede kursudvikling er første reality check. Hvis Novo, Eli Lilly og S&P 500 udviklede sig nogenlunde parallelt, ville en markedsforklaring være mere oplagt. Men Novo har en langt mere ekstrem udvikling: først en kraftig rerating opad og derefter et fald, der er meget dybere end det brede marked.
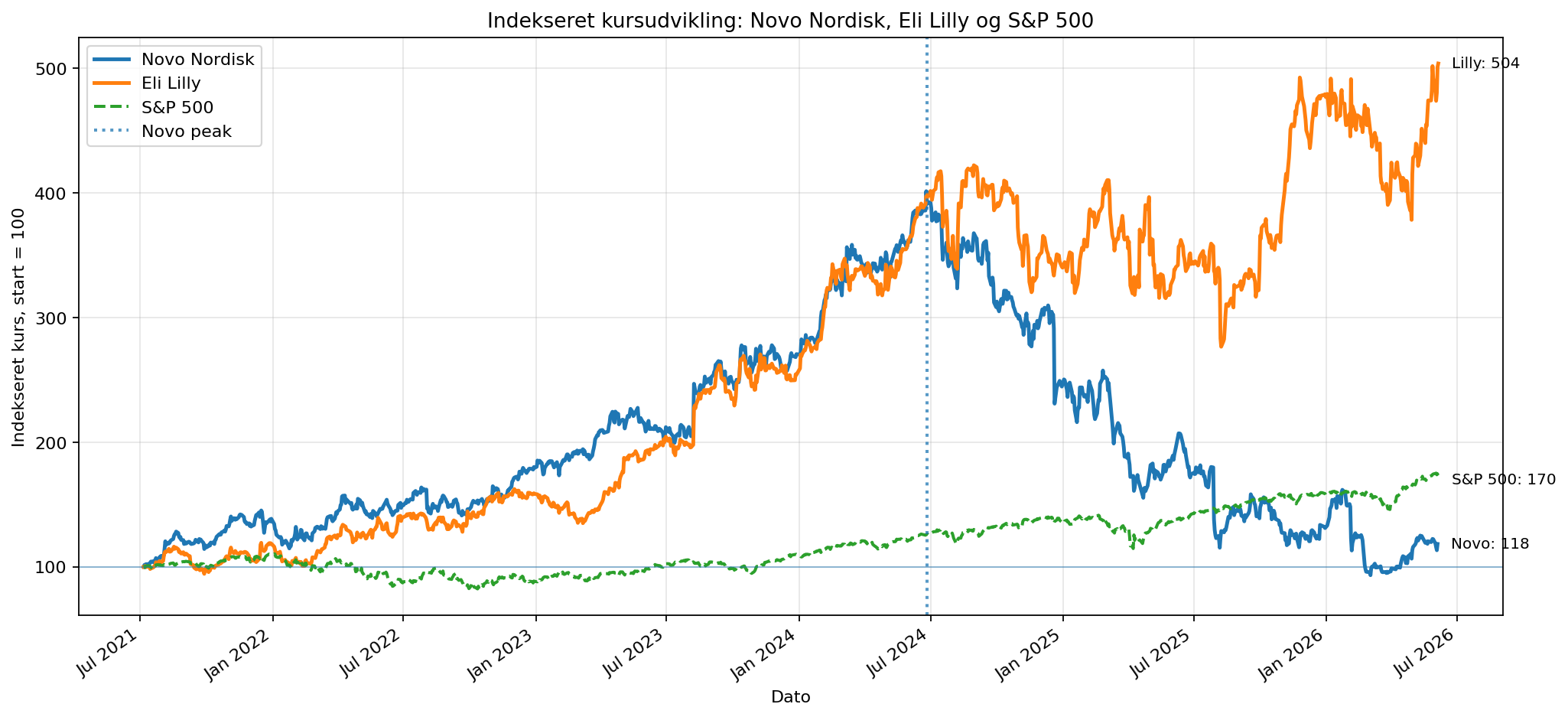
assets/01_indekseret_kursudvikling.png.Full-period beta er 0,2544. Det betyder, at når S&P 500 bevæger sig 1% på en dag, bevæger Novo sig i gennemsnit ca. 0,25% samme vej. P-værdien er 0,000128, så sammenhængen er statistisk signifikant. Men R² er kun 0,0122, altså 1,22%.
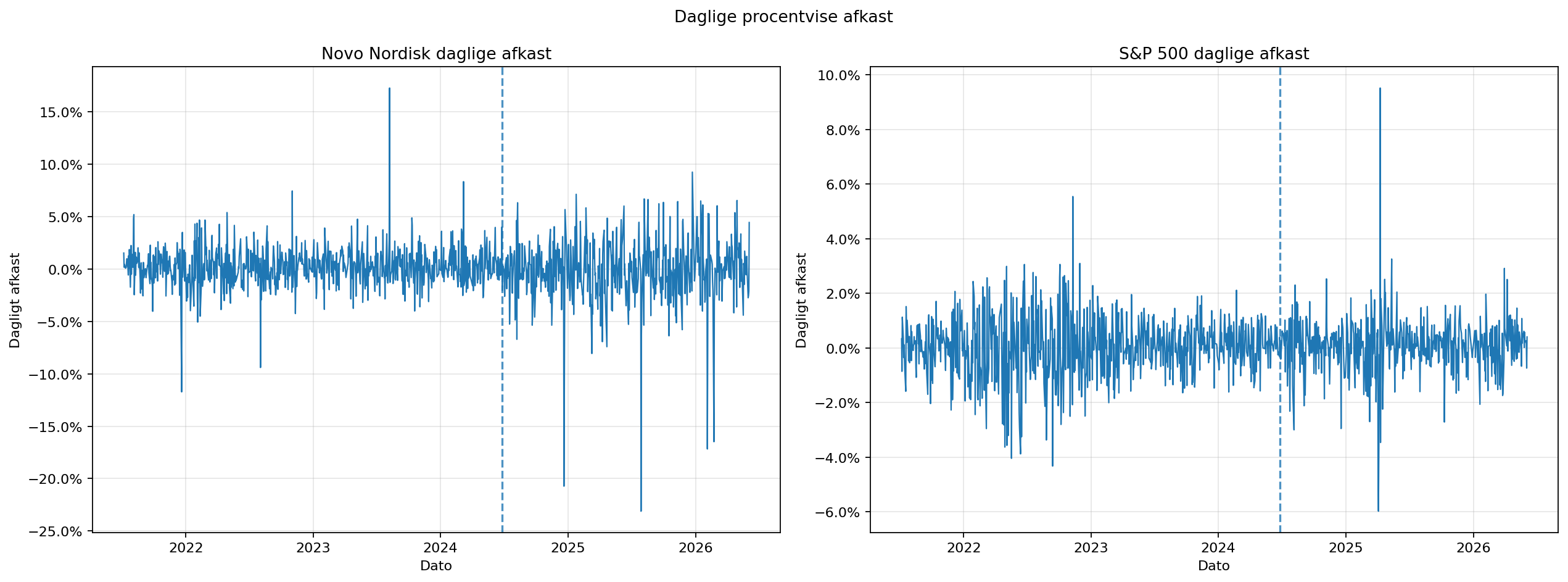
assets/02_daglige_afkast.png.| Periode | Alpha | Beta | R² | P-værdi | Std. error | Obs. |
|---|---|---|---|---|---|---|
| Hele perioden | 0,000208 | 0,254447 | 0,012207 | 0,000128 | 0,066213 | 1.197 |
| Før peak | 0,001883 | 0,169891 | 0,009788 | 0,007595 | 0,063462 | 727 |
| Efter peak | -0,002472 | 0,409769 | 0,018265 | 0,003329 | 0,138869 | 470 |
Før peak er beta 0,1699 og R² 0,98%. Efter peak stiger beta til 0,4098, altså ca. 2,4 gange højere end før peak. Det kunne ligne, at Novo bliver mere markedsfølsom i nedturen. Men R² stiger kun til 1,83%, hvilket stadig er meget lavt.
assets/03_split_period_beta.png.Rolling beta bruges som et dynamisk check på, om markedsfølsomheden ændrer sig gradvist. Rolling volatilitet viser samtidig, hvornår usikkerheden reelt kommer ind i aktien. Her er det vigtige ikke bare, at Novo har spikes, men at de kan kobles til konkrete nyheder: SELECT-resultater, CagriSema-skuffelse, nedjustering, 2026-outlook og efterfølgende bund/repricing.

assets/04_rolling_beta.png.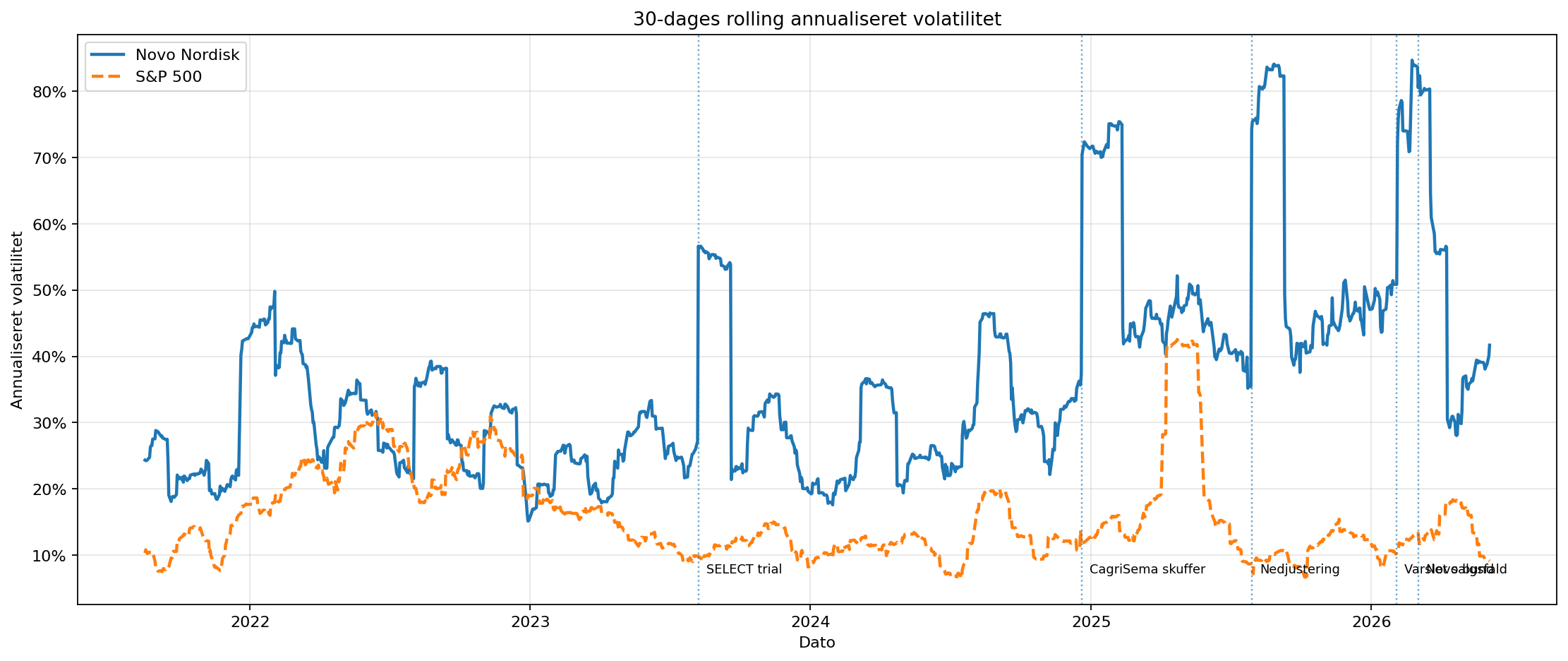
assets/05_rolling_volatilitet.png.Korrelationen mellem Novo og Eli Lilly er 0,2869, og beta mod Lilly er 0,3502. R² er 8,23%, hvilket stadig ikke er højt, men det er markant højere end R² mod S&P 500 på 1,22% — cirka 6,7 gange højere.
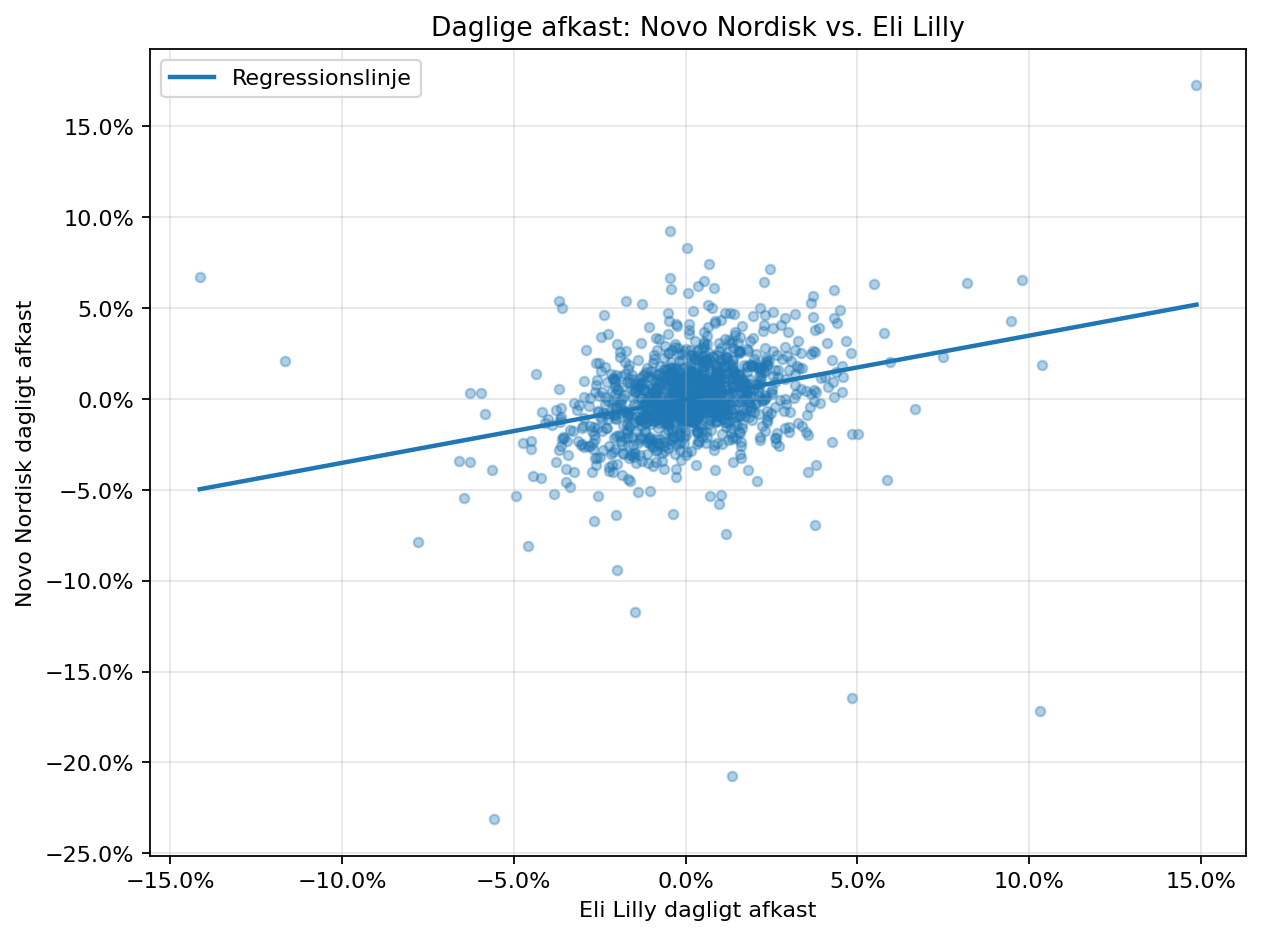
assets/06_novo_vs_lilly_regression.png.Event study'et måler, hvor meget Novo bevæger sig ud over det forventede, givet S&P 500's bevægelse. Det tydeligste resultat er nedjusteringen den 29. juli 2025: Novo faldt 31,70% i eventvinduet, mens S&P 500 faldt 2,36%. Den kumulative abnormal return er -32,71%.
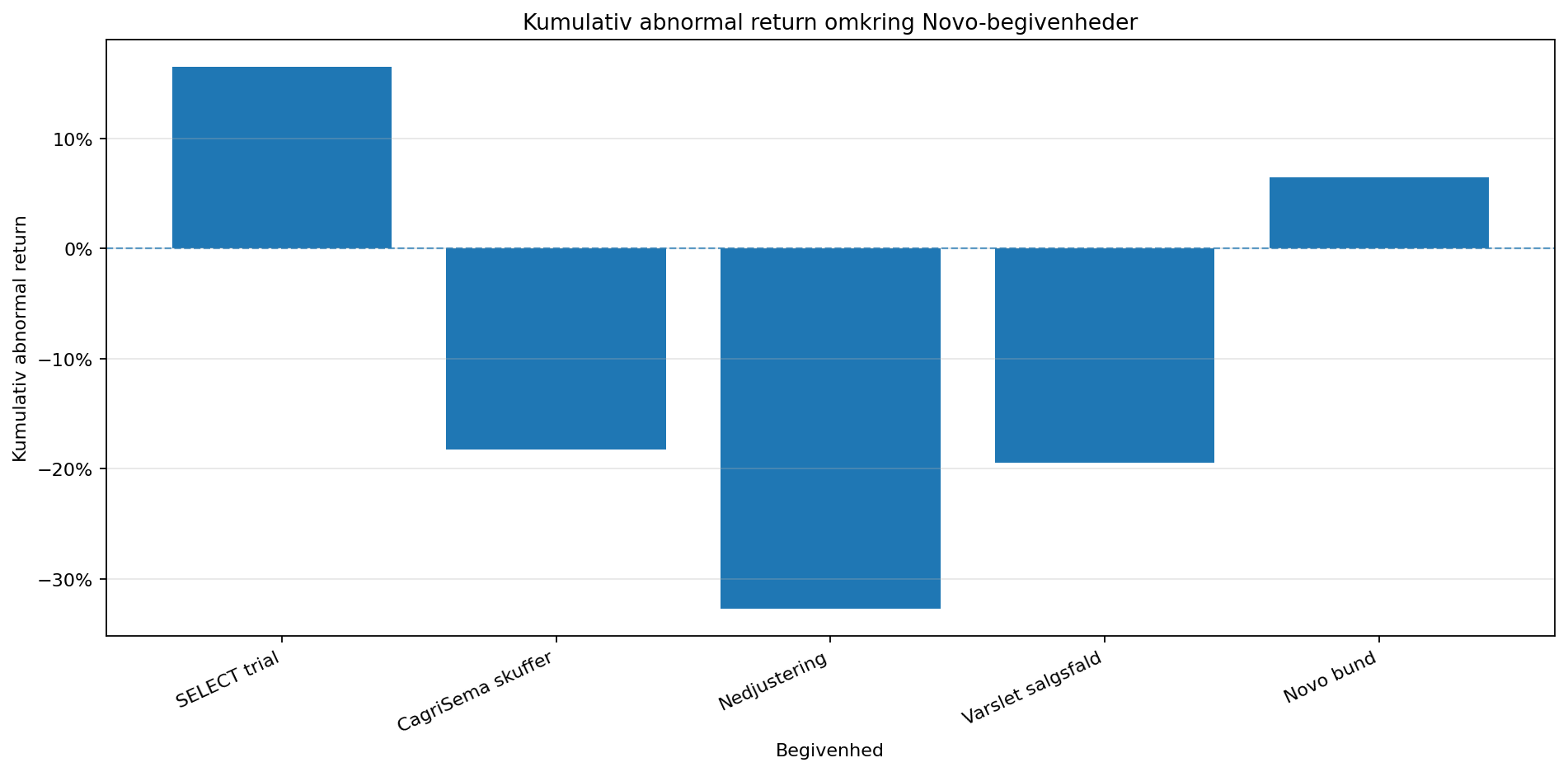
assets/07_event_study_abnormal_returns.png.| Event | Dato | Faktisk afkast | S&P 500 | Abnormal return | Vinduet |
|---|---|---|---|---|---|
| SELECT trial | 2023-08-08 | +16,92% | -0,31% | +16,48% | [-1,+3] |
| CagriSema skuffer | 2024-12-20 | -19,10% | -0,47% | -18,25% | [-1,+3] |
| Nedjustering | 2025-07-29 | -31,70% | -2,36% | -32,71% | [-1,+3] |
| Varslet salgsfald | 2026-02-03 | -20,04% | -0,10% | -19,43% | [-1,+3] |
| Novo bund | 2026-03-03 | +4,20% | -2,02% | +6,49% | [-1,+3] |
Max drawdown er -77,70% for Novo Nordisk, -42,57% for Eli Lilly og -29,66% for S&P 500. Novo's drawdown er dermed ca. 2,6 gange S&P 500's drawdown og ca. 1,8 gange Eli Lillys drawdown.
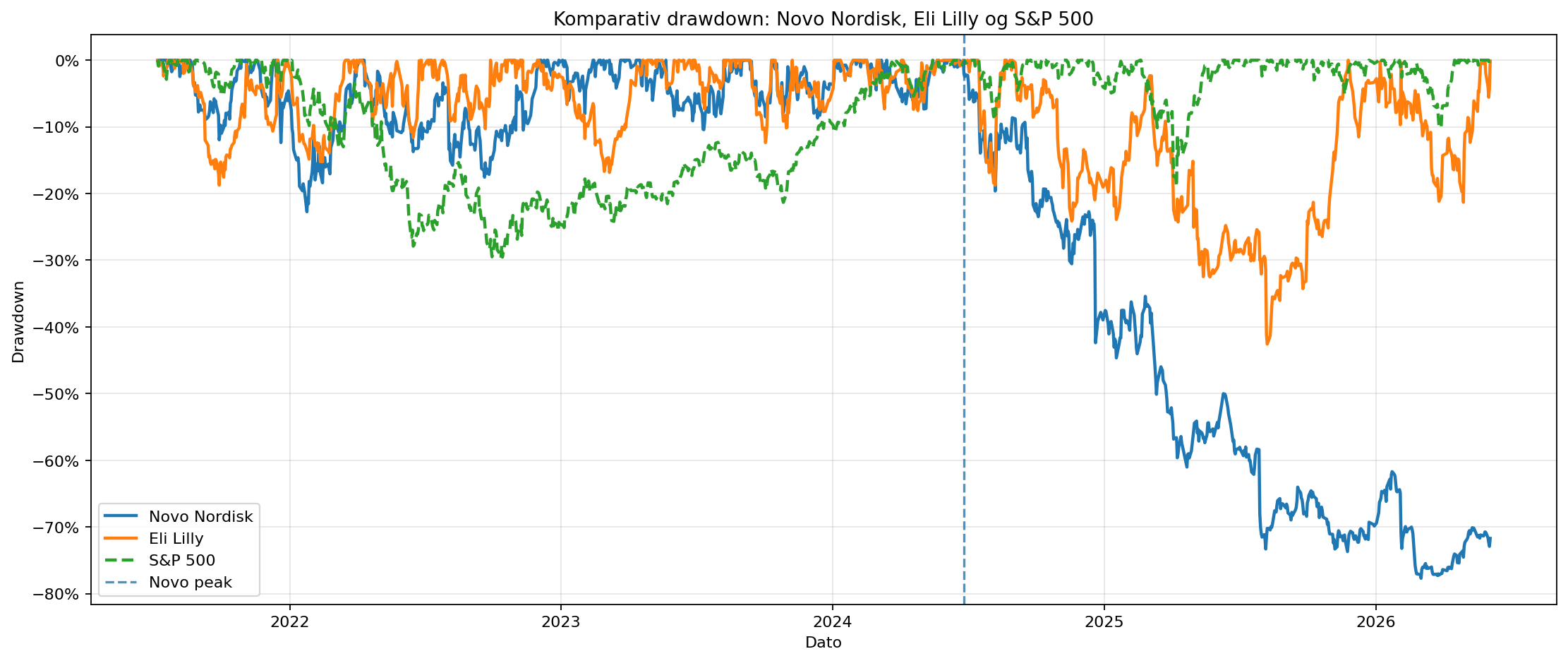
assets/08_komparativ_drawdown.png.Den korte version er ikke “Novo følger ikke markedet”, men noget mere præcist.
Analysen viser, at Novo Nordisk kun i meget begrænset grad kan forklares af S&P 500. Full-period beta er 0,2544, men R² er kun 1,22%. Det betyder, at markedet statistisk set har en effekt, men at effekten forklarer meget lidt af de daglige udsving.
Den mere interessante konklusion kommer fra split-period analysen. Efter peak stiger beta fra 0,1699 til 0,4098, men R² forbliver lav. Det peger på, at Novo bliver mere følsom i nedturen, men at aktiens store bevægelser stadig primært må forstås gennem Novo-specifik information og ikke gennem markedet alene.
Event study'et er det stærkeste argument: SELECT gav +16,48% abnormal return, mens CagriSema, nedjusteringen og 2026-outlook gav store negative abnormal returns. Det matcher også kilderne: SELECT ændrede investorernes syn på Wegovys potentielle medicinske og kommercielle værdi, mens CagriSema, lavere guidance, prispres og øget konkurrence ændrede risikobilledet.
Min samlede fortolkning er derfor, at Novo Nordisks aktie ikke bør analyseres som en simpel markeds-beta-historie. Den bør forstås som en aktie med lav markedsforklaringskraft, tydeligt regimeskift, stor event-følsomhed og en konkurrencerisiko, hvor Eli Lilly fylder mere end S&P 500 i forklaringen — men stadig uden at forklare alt.
Analysen er brugbar, men ikke perfekt. Her er de vigtigste svagheder.
Novo handles i København, mens S&P 500 og Lilly handles i USA. Same-day regression kan derfor undervurdere eller forvrænge sammenhænge.
Peak-datoen er valgt efter at man har set forløbet. En mere stringent analyse kunne teste flere mulige brudpunkter systematisk.
Event study viser timing og abnormal returns, men beviser ikke alene kausalitet. Kilder og markedsreaktioner bruges derfor som fortolkningsstøtte.
Kilderne bruges til at binde de kvantitative resultater sammen med konkrete selskabsnyheder og markedsfortællinger.
Bruges til at forstå, hvorfor SELECT-eventet kunne ændre investorernes forventninger til Wegovy.
Bruges til eventet omkring CagriSema og markedets reaktion på headline-resultaterne.
Bruges til at fortolke nedjusteringen og den store negative abnormal return.
Bruges til at forklare eventet med varslet salgs- og profitfald.
Bruges som baggrund for salgsudvikling, produktmix og risikofaktorer i 2025.
Bruges som supplerende ekstern kilde til 2026-risikobilledet.
Koden gemmer figurerne i assets/, som HTML-siden forventer. Billednavnene er de samme som i layoutet.
# ============================================================
# Novo Nordisk-analyse
# Formål:
# Undersøge om Novo Nordisks kursudvikling kan forklares af
# generelle markedsbevægelser, eller om den primært drives af
# selskabsspecifikke events, regimeskift og konkurrence mod Eli Lilly.
# ============================================================
from pathlib import Path
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
import matplotlib.dates as mdates
import yfinance as yf
from scipy import stats
# ------------------------------------------------------------
# 1) Opsætning
# ------------------------------------------------------------
Path("assets").mkdir(exist_ok=True)
novo = "NOVO-B.CO" # Novo Nordisk B, København
sp500 = "^GSPC" # S&P 500
lilly = "LLY" # Eli Lilly
START = "2021-07-06"
SLUT = "2026-06-09" # fastlåst, så analysen ikke ændrer sig automatisk
novo_peak_date = pd.to_datetime("2024-06-26")
novo_events = {
"SELECT trial": "2023-08-08",
"CagriSema skuffer": "2024-12-20",
"Nedjustering": "2025-07-29",
"Varslet salgsfald": "2026-02-03",
"Novo bund": "2026-03-03",
}
sp500_events = {
"Liberation Day": "2025-04-02",
}
# ------------------------------------------------------------
# 2) Data
# ------------------------------------------------------------
def hent_close(ticker: str) -> pd.Series:
"""Henter autojusteret slutkurs fra Yahoo Finance."""
data = yf.download(
ticker,
start=START,
end=SLUT,
auto_adjust=True,
progress=False,
)
if data.empty:
raise ValueError(f"Ingen data hentet for {ticker}")
return data["Close"].squeeze().dropna()
pris_novo = hent_close(novo)
pris_sp500 = hent_close(sp500)
pris_lilly = hent_close(lilly)
# ------------------------------------------------------------
# 3) Indekseret kursudvikling
# ------------------------------------------------------------
common_start = max(
pris_novo.index[0],
pris_sp500.index[0],
pris_lilly.index[0],
)
idx_novo = (pris_novo / pris_novo.loc[common_start]) * 100
idx_sp500 = (pris_sp500 / pris_sp500.loc[common_start]) * 100
idx_lilly = (pris_lilly / pris_lilly.loc[common_start]) * 100
fig, ax = plt.subplots(figsize=(13, 6))
ax.plot(idx_novo, linewidth=2.2, label="Novo Nordisk")
ax.plot(idx_lilly, linewidth=2.2, label="Eli Lilly")
ax.plot(idx_sp500, linewidth=1.8, linestyle="--", label="S&P 500")
ax.axhline(100, linewidth=0.9, alpha=0.45)
ax.axvline(novo_peak_date, linestyle=":", linewidth=1.8, alpha=0.75, label="Novo peak")
for series, name in [(idx_novo, "Novo"), (idx_lilly, "Lilly"), (idx_sp500, "S&P 500")]:
last_val = series.dropna().iloc[-1]
last_date = series.dropna().index[-1]
ax.annotate(
f"{name}: {last_val:.0f}",
xy=(last_date, last_val),
xytext=(8, 0),
textcoords="offset points",
fontsize=9,
va="center",
)
ax.set_title("Indekseret kursudvikling: Novo Nordisk, Eli Lilly og S&P 500")
ax.set_xlabel("Dato")
ax.set_ylabel("Indekseret kurs, start = 100")
ax.xaxis.set_major_formatter(mdates.DateFormatter("%b %Y"))
ax.xaxis.set_major_locator(mdates.MonthLocator(bymonth=[1, 7]))
ax.grid(True, alpha=0.3)
ax.legend()
fig.autofmt_xdate(rotation=35)
plt.tight_layout()
plt.savefig("assets/01_indekseret_kursudvikling.png", dpi=160, bbox_inches="tight")
plt.show()
# ------------------------------------------------------------
# 4) Afkast
# ------------------------------------------------------------
returns_novo = pris_novo.pct_change()
returns_sp500 = pris_sp500.pct_change()
returns_lilly = pris_lilly.pct_change()
aligned = pd.concat(
[returns_novo, returns_sp500, returns_lilly],
axis=1,
sort=False,
).dropna()
aligned.columns = ["novo", "sp500", "lilly"]
fig, axes = plt.subplots(1, 2, figsize=(16, 6))
axes[0].plot(aligned["novo"], linewidth=1)
axes[0].axvline(novo_peak_date, linestyle="--", linewidth=1.5, alpha=0.8)
axes[0].set_title("Novo Nordisk daglige afkast")
axes[0].set_xlabel("Dato")
axes[0].set_ylabel("Dagligt afkast")
axes[0].yaxis.set_major_formatter(mticker.PercentFormatter(1.0))
axes[0].grid(True, alpha=0.3)
axes[1].plot(aligned["sp500"], linewidth=1)
axes[1].axvline(novo_peak_date, linestyle="--", linewidth=1.5, alpha=0.8)
axes[1].set_title("S&P 500 daglige afkast")
axes[1].set_xlabel("Dato")
axes[1].set_ylabel("Dagligt afkast")
axes[1].yaxis.set_major_formatter(mticker.PercentFormatter(1.0))
axes[1].grid(True, alpha=0.3)
plt.suptitle("Daglige procentvise afkast")
plt.tight_layout()
plt.savefig("assets/02_daglige_afkast.png", dpi=160, bbox_inches="tight")
plt.show()
# ------------------------------------------------------------
# 5) Regression
# ------------------------------------------------------------
def run_regression(y: pd.Series, x: pd.Series) -> dict:
"""Returnerer alpha, beta, R², p-værdi, standardfejl og antal observationer."""
regression_data = pd.concat([y, x], axis=1).dropna()
regression_data.columns = ["y", "x"]
beta, alpha, r_value, p_value, std_err = stats.linregress(
regression_data["x"],
regression_data["y"],
)
return {
"alpha": alpha,
"beta": beta,
"r_squared": r_value**2,
"p_value": p_value,
"std_error": std_err,
"n_obs": len(regression_data),
}
reg_full = run_regression(aligned["novo"], aligned["sp500"])
print("── Full-period regression: Novo vs. S&P 500 ───────────────")
print(f"Beta: {reg_full['beta']:.4f}")
print(f"Alpha: {reg_full['alpha']:.6f}")
print(f"R²: {reg_full['r_squared']:.4f}")
print(f"P-værdi: {reg_full['p_value']:.6f}")
print(f"Std. error: {reg_full['std_error']:.6f}")
print(f"Obs.: {reg_full['n_obs']}")
# ------------------------------------------------------------
# 6) Split-period regression
# ------------------------------------------------------------
pre_peak = aligned.loc[aligned.index < novo_peak_date]
post_peak = aligned.loc[aligned.index >= novo_peak_date]
reg_pre = run_regression(pre_peak["novo"], pre_peak["sp500"])
reg_post = run_regression(post_peak["novo"], post_peak["sp500"])
split_regression_results = pd.DataFrame(
[reg_full, reg_pre, reg_post],
index=["Hele perioden", "Før peak", "Efter peak"],
)
print("\n── Split-period regression: Novo vs. S&P 500 ───────────────")
print(split_regression_results)
fig, ax = plt.subplots(figsize=(9, 5))
split_regression_results["beta"].plot(kind="bar", ax=ax)
ax.axhline(0, linestyle="--", linewidth=1, alpha=0.7)
ax.set_title("Beta før og efter Novo-peak")
ax.set_xlabel("Periode")
ax.set_ylabel("Beta mod S&P 500")
ax.grid(True, axis="y", alpha=0.3)
plt.xticks(rotation=0)
plt.tight_layout()
plt.savefig("assets/03_split_period_beta.png", dpi=160, bbox_inches="tight")
plt.show()
# ------------------------------------------------------------
# 7) Rolling beta
# ------------------------------------------------------------
rolling_window = 252
rolling_cov = aligned["novo"].rolling(rolling_window).cov(aligned["sp500"])
rolling_var = aligned["sp500"].rolling(rolling_window).var()
rolling_beta_12m = rolling_cov / rolling_var
fig, ax = plt.subplots(figsize=(14, 6))
ax.plot(rolling_beta_12m, linewidth=2, label="12-måneders rolling beta")
ax.axhline(0, linestyle="--", linewidth=1, alpha=0.6)
ax.axvline(novo_peak_date, linestyle="--", linewidth=1.5, alpha=0.8, label="Novo peak")
ax.set_title("Novo Nordisk: 12-måneders rolling beta mod S&P 500")
ax.set_xlabel("Dato")
ax.set_ylabel("Beta")
ax.grid(True, alpha=0.3)
ax.legend()
plt.tight_layout()
plt.savefig("assets/04_rolling_beta.png", dpi=160, bbox_inches="tight")
plt.show()
# ------------------------------------------------------------
# 8) Rolling volatilitet
# ------------------------------------------------------------
rolling_vol_novo_annual = aligned["novo"].rolling(window=30).std() * np.sqrt(252)
rolling_vol_sp500_annual = aligned["sp500"].rolling(window=30).std() * np.sqrt(252)
fig, ax = plt.subplots(figsize=(14, 6))
ax.plot(rolling_vol_novo_annual, linewidth=2, label="Novo Nordisk")
ax.plot(rolling_vol_sp500_annual, linewidth=2, linestyle="--", label="S&P 500")
for label, date in novo_events.items():
event_date = pd.to_datetime(date)
ax.axvline(event_date, linestyle=":", linewidth=1.1, alpha=0.65)
ax.annotate(
label,
xy=(event_date, 0.05),
xycoords=("data", "axes fraction"),
xytext=(5, 0),
textcoords="offset points",
fontsize=8,
va="bottom",
)
for label, date in sp500_events.items():
event_date = pd.to_datetime(date)
ax.axvline(event_date, linestyle="--", linewidth=1.2, alpha=0.65)
ax.annotate(
label,
xy=(event_date, 0.90),
xycoords=("data", "axes fraction"),
xytext=(5, 0),
textcoords="offset points",
fontsize=8,
va="bottom",
)
ax.set_title("30-dages rolling annualiseret volatilitet")
ax.set_xlabel("Dato")
ax.set_ylabel("Annualiseret volatilitet")
ax.yaxis.set_major_formatter(mticker.PercentFormatter(1.0))
ax.grid(True, alpha=0.3)
ax.legend()
plt.tight_layout()
plt.savefig("assets/05_rolling_volatilitet.png", dpi=160, bbox_inches="tight")
plt.show()
# ------------------------------------------------------------
# 9) Novo vs. Eli Lilly
# ------------------------------------------------------------
novo_lilly_corr = aligned["novo"].corr(aligned["lilly"])
reg_novo_lilly = run_regression(y=aligned["novo"], x=aligned["lilly"])
print("\n── Novo vs. Eli Lilly ─────────────────────────────────────")
print(f"Korrelation: {novo_lilly_corr:.4f}")
print(f"Beta mod Lilly: {reg_novo_lilly['beta']:.4f}")
print(f"Alpha: {reg_novo_lilly['alpha']:.6f}")
print(f"R²: {reg_novo_lilly['r_squared']:.4f}")
print(f"P-værdi: {reg_novo_lilly['p_value']:.6f}")
print(f"Std. error: {reg_novo_lilly['std_error']:.6f}")
print(f"Obs.: {reg_novo_lilly['n_obs']}")
fig, ax = plt.subplots(figsize=(8, 6))
ax.scatter(aligned["lilly"], aligned["novo"], alpha=0.35, s=18)
x_vals = np.linspace(aligned["lilly"].min(), aligned["lilly"].max(), 100)
y_vals = reg_novo_lilly["alpha"] + reg_novo_lilly["beta"] * x_vals
ax.plot(x_vals, y_vals, linewidth=2, label="Regressionslinje")
ax.set_title("Daglige afkast: Novo Nordisk vs. Eli Lilly")
ax.set_xlabel("Eli Lilly dagligt afkast")
ax.set_ylabel("Novo Nordisk dagligt afkast")
ax.xaxis.set_major_formatter(mticker.PercentFormatter(1.0))
ax.yaxis.set_major_formatter(mticker.PercentFormatter(1.0))
ax.grid(True, alpha=0.3)
ax.legend()
plt.tight_layout()
plt.savefig("assets/06_novo_vs_lilly_regression.png", dpi=160, bbox_inches="tight")
plt.show()
# ------------------------------------------------------------
# 10) Event study
# ------------------------------------------------------------
def event_study(
returns_data: pd.DataFrame,
event_dict: dict,
estimation_window: int = 252,
event_window_before: int = 1,
event_window_after: int = 3,
) -> pd.DataFrame:
"""Beregner kumulativ abnormal return omkring events."""
results = []
for event_name, event_date_str in event_dict.items():
event_date = pd.to_datetime(event_date_str)
valid_dates = returns_data.index[returns_data.index >= event_date]
if len(valid_dates) == 0:
continue
trading_event_date = valid_dates[0]
event_pos = returns_data.index.get_loc(trading_event_date)
estimation_start_pos = event_pos - estimation_window - event_window_before
estimation_end_pos = event_pos - event_window_before
event_start_pos = event_pos - event_window_before
event_end_pos = event_pos + event_window_after
if estimation_start_pos < 0 or event_end_pos >= len(returns_data):
continue
estimation_data = returns_data.iloc[estimation_start_pos:estimation_end_pos]
event_data = returns_data.iloc[event_start_pos:event_end_pos + 1]
reg_event = run_regression(
y=estimation_data["novo"],
x=estimation_data["sp500"],
)
expected_return = reg_event["alpha"] + reg_event["beta"] * event_data["sp500"]
abnormal_return = event_data["novo"] - expected_return
results.append({
"event": event_name,
"dato": event_date.date(),
"handelsdato": trading_event_date.date(),
"beta_estimat": reg_event["beta"],
"alpha_estimat": reg_event["alpha"],
"faktisk_afkast_window": (1 + event_data["novo"]).prod() - 1,
"sp500_afkast_window": (1 + event_data["sp500"]).prod() - 1,
"abnormal_return_window": abnormal_return.sum(),
"event_window": f"[-{event_window_before}, +{event_window_after}]",
})
return pd.DataFrame(results)
event_results = event_study(
returns_data=aligned[["novo", "sp500"]],
event_dict=novo_events,
estimation_window=252,
event_window_before=1,
event_window_after=3,
)
print("\n── Event study: abnormal returns ───────────────────────────")
print(event_results)
fig, ax = plt.subplots(figsize=(12, 6))
ax.bar(event_results["event"], event_results["abnormal_return_window"])
ax.axhline(0, linestyle="--", linewidth=1, alpha=0.7)
ax.set_title("Kumulativ abnormal return omkring Novo-begivenheder")
ax.set_xlabel("Begivenhed")
ax.set_ylabel("Kumulativ abnormal return")
ax.yaxis.set_major_formatter(mticker.PercentFormatter(1.0))
ax.grid(True, axis="y", alpha=0.3)
plt.xticks(rotation=25, ha="right")
plt.tight_layout()
plt.savefig("assets/07_event_study_abnormal_returns.png", dpi=160, bbox_inches="tight")
plt.show()
# ------------------------------------------------------------
# 11) Drawdown
# ------------------------------------------------------------
def calculate_drawdown(return_series: pd.Series) -> tuple[pd.Series, float]:
cumulative_return = (1 + return_series.dropna()).cumprod()
rolling_peak = cumulative_return.cummax()
drawdown = (cumulative_return - rolling_peak) / rolling_peak
return drawdown, drawdown.min()
drawdown_novo, max_dd_novo = calculate_drawdown(aligned["novo"])
drawdown_sp500, max_dd_sp500 = calculate_drawdown(aligned["sp500"])
drawdown_lilly, max_dd_lilly = calculate_drawdown(aligned["lilly"])
drawdown_summary = pd.DataFrame({
"Max drawdown": [max_dd_novo, max_dd_lilly, max_dd_sp500],
}, index=["Novo Nordisk", "Eli Lilly", "S&P 500"])
print("\n── Komparativ max drawdown ────────────────────────────────")
print(drawdown_summary)
fig, ax = plt.subplots(figsize=(14, 6))
ax.plot(drawdown_novo, linewidth=2, label="Novo Nordisk")
ax.plot(drawdown_lilly, linewidth=2, label="Eli Lilly")
ax.plot(drawdown_sp500, linewidth=2, linestyle="--", label="S&P 500")
ax.axvline(novo_peak_date, linestyle="--", linewidth=1.5, alpha=0.8, label="Novo peak")
ax.set_title("Komparativ drawdown: Novo Nordisk, Eli Lilly og S&P 500")
ax.set_xlabel("Dato")
ax.set_ylabel("Drawdown")
ax.yaxis.set_major_formatter(mticker.PercentFormatter(1.0))
ax.grid(True, alpha=0.3)
ax.legend()
plt.tight_layout()
plt.savefig("assets/08_komparativ_drawdown.png", dpi=160, bbox_inches="tight")
plt.show()
# ------------------------------------------------------------
# 12) Eksport
# ------------------------------------------------------------
split_regression_results.to_csv("assets/split_regression_results.csv")
event_results.to_csv("assets/event_study_results.csv", index=False)
drawdown_summary.to_csv("assets/drawdown_summary.csv")
print("\nFigurer og tabeller er gemt i assets/-mappen.")